
티스토리 뷰
테슬라하면 떠오르는 단어가 2개 있습니다. 바로 자율주행과 전기차죠. 이번 글에서는 테슬라 자율주행이 어떻게 AI 알고리즘으로 구현되었는지 알아보겠습니다. 이 글의 내용은 대부분 Tesla AI Day 2021 발표 내용을 기반으로 했습니다.
테슬라 자율주행 시스템의 구성
테슬라 자율주행 시스템은 아래와 같이 크게 3 부분으로 구성되어 있습니다. 첫번째로 가장 중요한 "Vision" 부문입니다. Vision은 차량 주변을 인식하고 사물의 움직임을 예측하는 시스템으로 여기서 인식한 정보가 차량 운행의 기본이 되기 때문에 중요합니다. 실제 Tesla AI Day 2021에서도 상당 시간을 Vision 시스템에 할당해 설명하고 있습니다. 그 다음은 차량을 어떻게 운행할지 계획하는 "Neural Net Planner"이며 여기에는 Alpha Go에서 적용되었던 MCTS(Monte Carlo Tree Simulation)을 적용합니다. 마지막으로 앞의 두 모델의 정보 및 예측을 바탕으로 실제 차량을 주행하는 "Explicit Planning & Contol"이 있습니다.
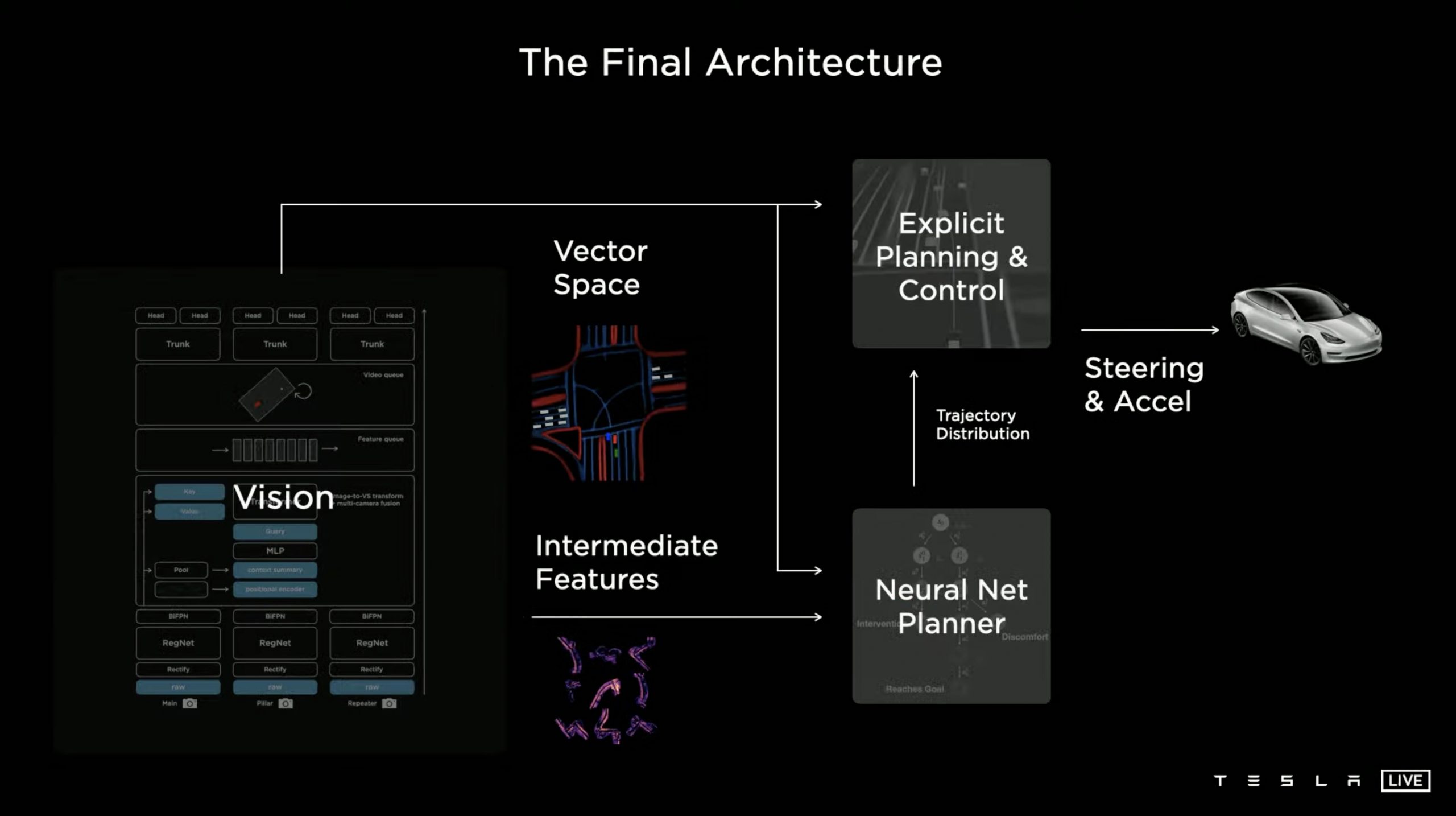
Vision 시스템 (1) - 주변 사물의 인식
테슬라 Vision 시스템은 우선 8개의 카메라로부터 들어온 정보를 종합하여 주변 상황을 파악하여 BEV(birds eye view) 지도를 만들어냅니다. BEV 지도는 아래와 같이 새가 바라보듯 하늘에서 바라본 차량과 그 주변의 모습입니다. 논란의 여지가 많지만 테슬라는 다른 자율주행 진영과 달리 Lidar 없이 카메라로만 주변 사물의 인식이 가능하다고 주장합니다. 인간도 라이더 없이 두 눈으로 운전을 하며 실험 결과 8개의 카메라만으로도 상당 부문 인식 정확도를 달성했다는 것이 근거입니다. 여기서는 카메라만을 사용하는 테슬라 방식의 적합성에 대해서는 이야기하지 않겠습니다.
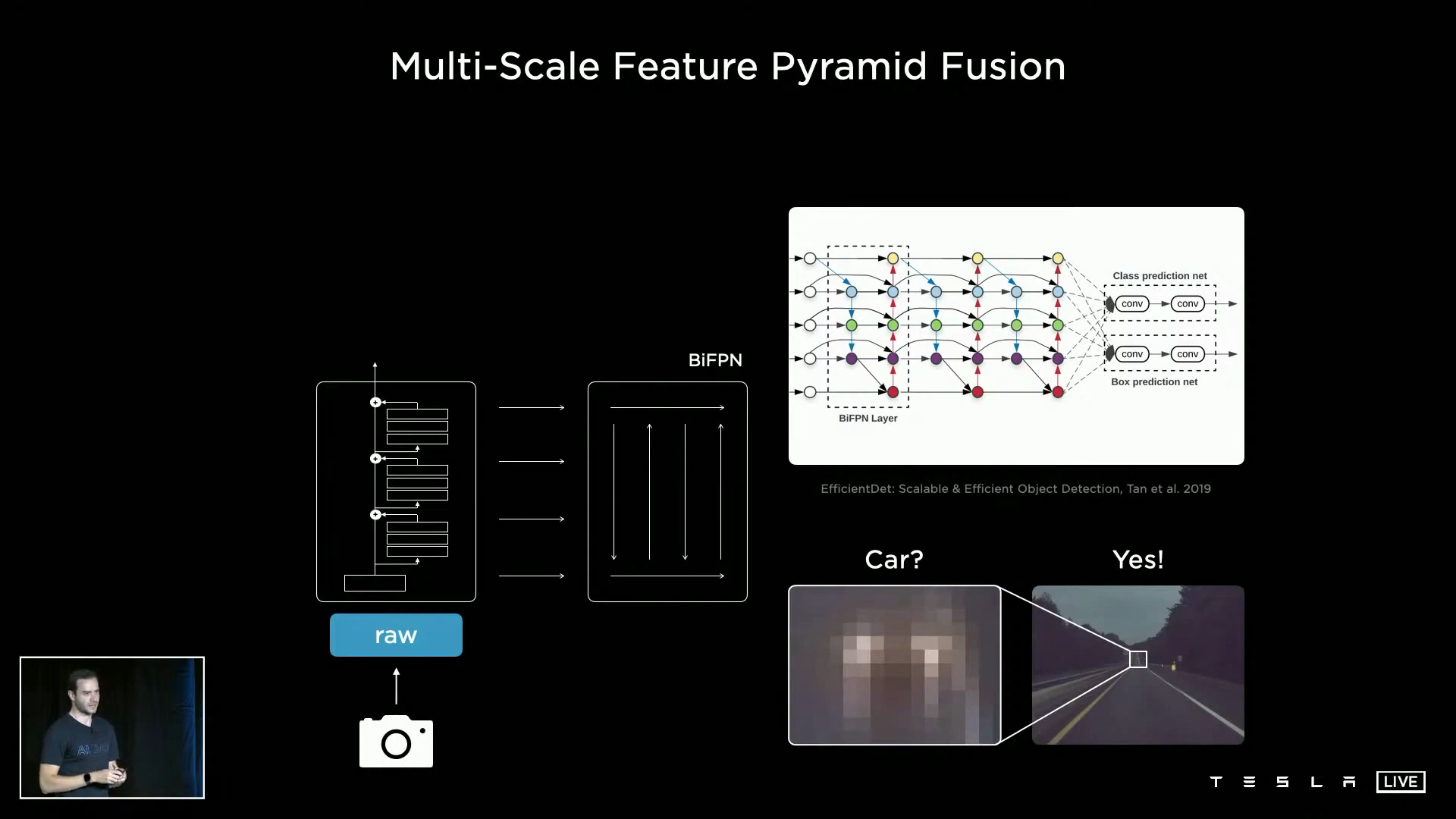
각 카메라의 정보 처리 - BiFPN
우선 각 카메라로 들어온 화면 정보는 BiFPN을 거치면서 중요한 특성(Feature)이 추출됩니다. BiFPN(bi-directional feature pyramid network)은 Google Brain 연구진이 제안한 일종의 영상/화면 인식 Framework라고 할 수 있습니다. 기존의 영상/화면 인식 알고리즘이 마지막 Layer의 작은 사이즈 Feature만 활용했던 것 대비, BiFPN에서는 여러 Layer의 다양한 사이즈 Feature를 모두 사용하여 인식의 정확도를 높이고자 하는 방식이죠. 이 방식을 적용할 경우, 인식에 활용하는 Feature가 많아져 연산량 및 메모리에 부담이 있기는 하지만 정확도가 중요한 자율주행에는 적합하다고 할 수 있습니다.
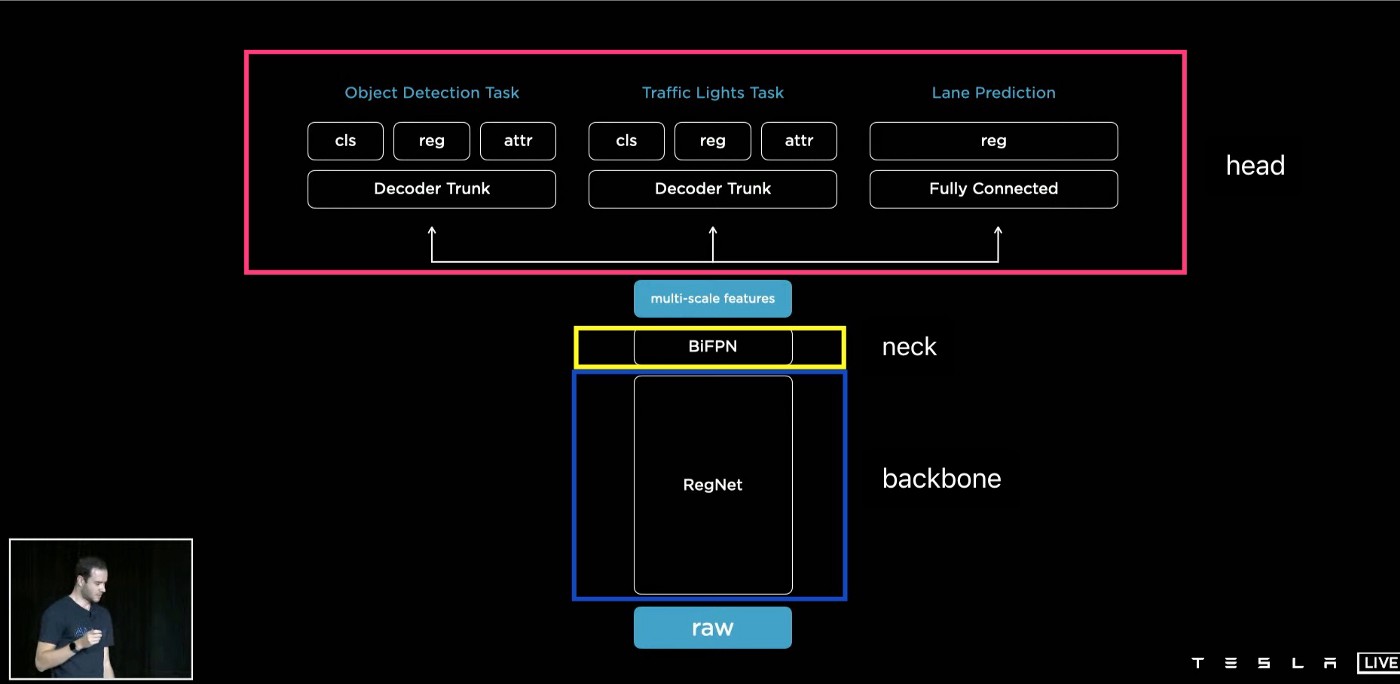
사물 인식 - HydraNet
BiFPN을 통해 추출한 Feature가 실제로 어떠한 사물에 해당하는지를 판단하는 단계에는 구글 연구팀이 개발한 HydraNet 프레임워크를 사용했습니다. HydraNet은 영상 인식의 속도를 높이기 위해 도입한 기법으로 "대분류->소분류" 2단계 인식으로 이해할 수 있습니다. 영상인식은 사진 속 사물이 미리 정의된 다수의 Category 중 어디에 해당하는지 확률을 계산하는 기법입니다. 따라서 Category 수가 많을 수록 더 많은 사물을 인식할 수 있지만 각 Category마다 해당 확률을 계산해야 하니 연산량이 늘어나고 시간도 많이 걸리겠죠. 따라서 구글 연구팀은 Category를 2단계로 나누고 각 단계의 Category 수는 적게 하여 전체적인 연산 시간을 단축하는 아이디어를 제안했습니다. 테슬라의 사례에 적용한다면 대분류는 아래 그림과 같이 Feature가 "사물, 차선, 도로표지판, 신호등" 중 어디에 속하는지에 해당합니다. 만약 대분류에서 사물로 구분되었다면 사물 중 소분류는 "사람, 자전거, 차량, 건물" 중 어디에 해당하는지로 파악할 수 있습니다.
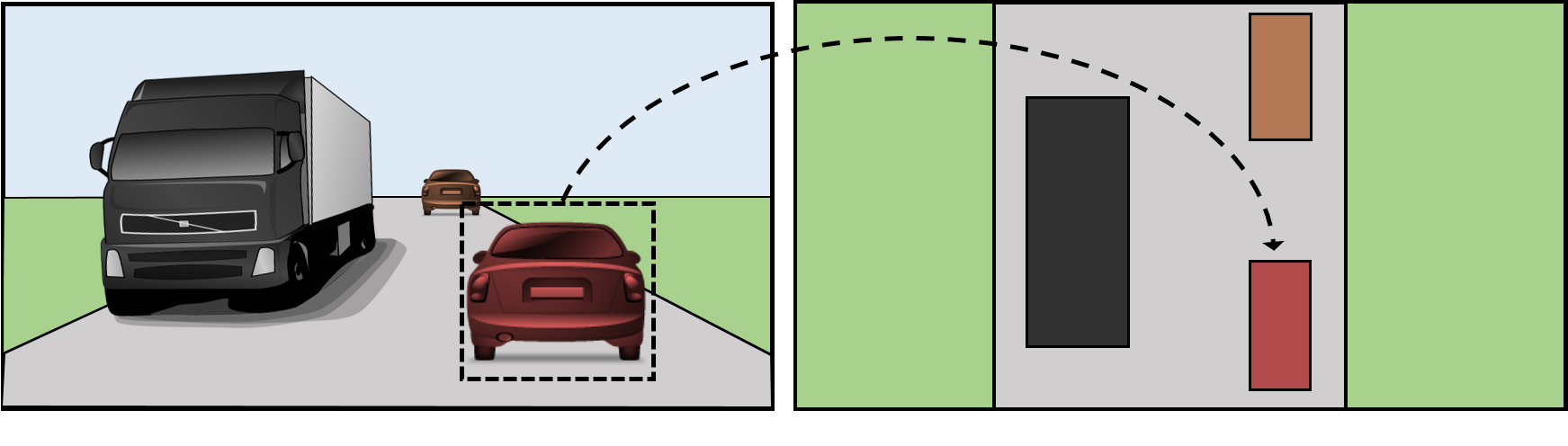
카메라 정보의 통합 - Multicam Fusion and Transformation
각 카메라에서 중요한 Feature를 뽑았으니 이제 이를 통합하여 차량 주변의 BEV(bird's eye view) 지도를 만드는 "Multicam Fusion and Transformation" 단계를 거칩니다. BEV란 말 그대로 하늘에서 바라본 내 차량과 주변 사물의 위치가 나타난 지도입니다. 이 정보가 있어야 도로 위의 어느 방향으로 어는 거리에 무슨 사물이 있는지 인식할 수 있어 안전한 주행이 가능하겠죠. BEV를 만들기 위한 첫 번째 단계는 각 카메라에서 들어온 정보의 통합입니다. 우선 여러 카메라를 활용하는 이유는 각 카메라마다 사각 지대가 있을 수 있어서 이러한 위험을 보완하기 위함입니다. 따라서 아래와 같이 동일한 트럭이 여러 카메라에 찍히는 경우도 있겠. Multicam Fusion 단계에서는 각 카메라에 찍힌 동일한 사물을 인식하여 정확한 BEV를 그릴 수 있도록 합니다. 만약 동일 사물이 인식되지 않으면 지도 위에 동일 사물(차량)이 2, 3개로 나타날 수 있겠죠.

Transform이란 카메라로 찍힌 Image Space를 BEV 상의 Vector Space로 전환함을 의미합니다. 이를 위해서는 위에서 인식된 사물이 어느 방향에 어느 정도 거리에 있는지 수치가 계산되어야 하죠. 여러 카메라에 사물이 잡힌 경우 위치 정확도가 높아지는 장점이 있지만 계산 복잡도가 높아지는 단점도 존재합니다. 하여튼 짧은 시간 내에 Multicam Fusion and Transformation이 이뤄져야 합니다.

Vision 시스템 (2) - 주변 사물의 움직임 예측 (RNN 활용)
자율 주행을 위해서는 주변 사물의 위치 인지 뿐만 아니라 움직임 예측도 필수적으로 필요합니다. 예를 들어서 내가 오른쪽 차선으로 끼어들기를 하려고 할 때 그 주변의 차량이나 자전거 혹은 사람이 들어와서 충돌할 위험이 없는지 예측하고 위험이 없다고 판단되면 끼어들기를 하는 과정을 생각하면 자연스럽게 그 필요성이 확인돼죠.
테슬라의 자율주행 시스템에서는 RNN(recurrent neural network)를 이용해 주변 사물의 움직임을 예측합니다. RNN은 주로 음성인식에 활용되는 AI 알고리즘인데 Recurrent라는 용어에서 확인할 수 있듯이 연쇄적으로 앞 단어(음성)의 인식 결과를 바탕으로 다음 단어(음성)을 인식하는 방식입니다. 차량의 움직임도 언어과 같이 연속적이기 때문에 과거의 차량 움직임을 확인한다면 향후 차량의 움직임을 예측할 수 있다는 아이디어에서 RNN을 적용한 것 같습니다. 음성인식과 자율주행의 차이점은 음성인식은 1-Dimension인 음성/단어였지만 자율주행은 X, Y 좌표가 있는 2-Dimension의 Spatial RNN라는 것이 차이지요.
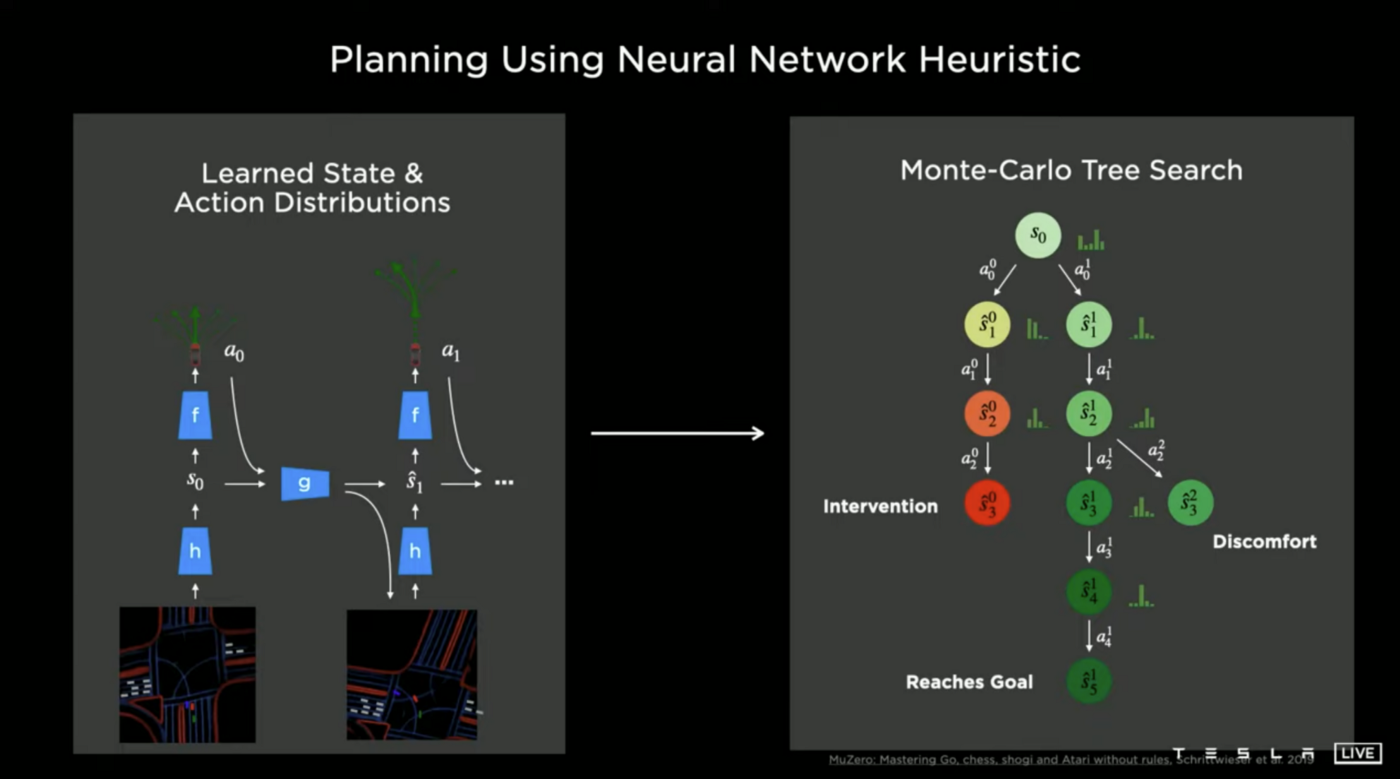
Neural Net Planner 시스템 - 최적 경로의 예측
Vision 시스템에서 도출된 주변 상황에 대한 정보를 바탕으로 "Neural Net Planner"는 최적 경로를 예측합니다. 여기서 사용되는 알고리즘은 Alpha Go에서도 사용되었던 MCTS(Monte Carlo Tree Search)입니다. MCTS는 간단히 설명하자면 다양한 경우의 수를 Tree 방식으로 탐색하여 결과를 예측한 후 이를 바탕으로 현재 시점의 최적의 의사결정을 내리는 방식입니다. 바둑을 예로 들자면 현재 내가 둘 수 있는 다양한 수가 있고 상대방의 반응까지 고려해서 앞으로의 몇(십) 수를 내다 본 다음, 승률이 가장 높을 것으로 예측되는 수를 두는 방식이지요. MCTS는 탐색해야 할 경우의 수를 얼마나 효과적으로 줄이고, 탐색 결과를 승률을 얼마나 정확히 예측하느냐에 따라 그 유용도가 결정됩니다. 운전도 내가 차를 어떻게 운행하며 그에 따라 다른 차들이 어떻게 반응할지에 대한 예측을 반영하여 목적지까지 빠르고 안전하게 갈 수 있는 최적 경로를 선택한다는 관점에서 MCTS 적용이 가능해보입니다.
실제 운전 - Explicit Planning & Control
최적 경로까지 설정했다면 이제는 주변 상황에 맞추어 실제로 차를 운전하는 "Explicit Planning & Control" 단계입니다. 운전이라고 하면 엑셀/브레이크 조작, 핸들 조작, 깜빡이 조작 등이 있겠지요. 해당 조작은 빠른 반응 속도로 정확하게 이뤄져야 하기 때문에 앞의 두 시스템(Vision 및 Neural Net Planner)의 결과를 신속하게 종합/반영하는 것이 필요하지요. Neural Net Planner와 겹친다고 생각할 수 있지만 Neural Net Planner는 좀 더 장기적 관점에서의 경로, Explicit Planning & Control은 단기적으로 실제 Action과 관계된다는 점에서 차이가 있습니다.
테슬라 자율주행의 완성도는? - 시내 주행이 관건
위와 같이 AI 알고리즘을 적용한 테슬라는 자율주행에 대해 상당한 자신감을 보이고 있지만 기술적으로 볼 때 앞으로 갈 길이 많아 보입니다. 테슬라는 우선 고속도로 주행에 FSD를 적용했고 21년에 시내 주행까지 가능한 Beta version을 발표했죠. 사고율 수치로 보자면 고속도로 주행에 있어 테슬라 자율 주행은 일반 운전자와 비슷하거나 나은 수준으로 보입니다. 물론 최근 코로나의 영향으로 차량 주행이 줄어들어 테슬라 자율 주행의 사고율이 낮아졌을 수도 있지만 어느 정도 수준에 올라온 것은 맞아 보입니다. 하지만 유튜브 등을 통해 시내 주행에서의 FSD를 보면, 정면이 아닌 사선에서 오는 차량은 확인하지 못하고, 골목길에서 큰 길로 나가는데 어려움을 겪는 등 고속도로보다 훨씬 복잡한 시내에서는 아직 사람 수준에 이르지 못한 것 같습니다. AI 모델 및 학습 데이터 강화를 통해 향후에 테슬라 자율주행 모델이 시내에서도 완벽한 모습을 보여줄지 지켜봐야겠습니다.
'IT' 카테고리의 다른 글
| 칩렛(Chiplet)이란? (2) | 2022.03.22 |
|---|---|
| 딥러닝 모델의 분산학습이란? (Data parallelism과 Model parallelism) (0) | 2021.07.24 |
| 자연어처리 모델 학습을 위한 하드웨어 구성은? (NVIDIA Grace) (0) | 2021.07.21 |
| 자연어 처리(NLP)란 무엇이며 누가 주도하는가? (0) | 2021.07.17 |
| Processing in memory(PIM)이란? (2) - Concept 및 사례 (1) | 2021.05.29 |